Eine Reise durch die Physiologie - Wie der Körper des Menschen funktioniert

Grundlagen
und Methoden der Physiologie; molekulare und zelluläre Aspekte

 Streuung,
Normalwerte, Biometrie, Hypothesenverifizierung
Streuung,
Normalwerte, Biometrie, Hypothesenverifizierung
©
H. Hinghofer-Szalkay
 Bayes-Theorem: Thomas Bayes
Bayes-Theorem: Thomas Bayes
Diagnose: διά = durch, γνώσις = Erkenntnis, Urteil
Falsifikation: falisificare = als falsch erkennen
Gauß'sche Glockenkurve: Carl Friedrich Gauß
Heuristik: εὑρίσκειν = entdecken, finden
Hypothese: ὑπόθεσις = Grundlage‚ Voraussetzung, Unterstellung
Placebo: placebit (lat) = es wird gefallen
Randomisieren: random = zufällig
Signifikanz: signum = (Kenn)Zeichen, Signal
stochastisch: στοχαστικὴ τέχνη = Ratekunst
Theorie: θεωρεῖν = betrachten, θεωρία = Sehen, Anschauung, wissenschaftliche Betrachtung, Überlegung, Einsicht
Varianz: variare = (ver)ändern, verschieden sein
Biometrie
(Biostatistik) verwendet mathematische Verfahren zur Organisation,
Darstellung und Beurteilung von Daten, die bei der wissenschaftlichen
Untersuchung biologischer Systeme gewonnen werden. Sie stellt Ergebnisse von Beobachtungen oder experimentellen Studien dar (beschreibende oder deskriptive Statistik), bietet Schätz- und Testverfahren, und ermöglicht die Prüfung von Hypothesen (schließende oder induktive Statistik).
Bei letzterer können zwei Arten von Fehleinschätzungen unterlaufen:
-- Fehler 1. Art, α-Fehler: Die Nullhypothese (Gruppen unterscheiden sich nicht) wird fälschlicherweise zurückgewiesen, obwohl sie zutrifft (falsch positive
Einschätzung: Ein Unterschied wird vermutet, obwohl es nicht da ist.
Beispiele: Krankheitsdiagnose beim Gesunden, zu strenger Prüfer - "Fehlalarm").
Hohe Spezifität bedeutet einen geringen Fehler 1. Art
-- Fehler 2. Art, β-Fehler: Die Nullhypothese wird fälschlicherweise beibehalten, obwohl sie nicht zutrifft (falsch negative Einschätzung - es wird etwas verpasst, obwohl es da ist. Beispiele: Nichterkennen einer Krankheit, allzu nachsichtiger Prüfer - "Laissez-faire").
Hohe Sensitivität bedeutet einen geringen Fehler 2. Art
Das
Ergebnis von Beobachtungen / Messungen unterliegt verschiedenen
Fehlerquellen. Beispielsweise stellt sich die Frage nach der
Genauigkeit:
-- Mit Präzision meint man, wie stark (bei wiederholter Messung) die Resultate streuen (quantifizierbar mittels eines Varianzmaßes, z.B. Standardabweichung);
-- Absolutgenauigkeit (accuracy)
gibt an, wie "richtig" das Messverfahren arbeitet (Nähe des
statistischen Mittelwertes der Resultate zum tatsächlichen Wert der
gemessenen Größe).
Testdesign bedeutet planvolles Vermeiden von Fehlern. So ermöglicht Randomisierung (zufällige Zuteilung zu Testgruppen), unbeabsichtigte systematische Fehler (bias) zu vermeiden, welche z.B. einen Effekt (etwa eine Medikamentenwirkung) vortäuschen, der in Wirklichkeit nicht besteht.
|
Daten müssen organisiert und interpretiert werden
Was
ist gesund ("normal", physiologisch), was ist krank (abnorm,
pathologisch)? Oft ist es nicht einfach, aufgrund einer Messung (z.B.
Blutdruck) oder eines Laborwertes (z.B. Blutzuckerspiegel) eine klare
Antwort zu finden, insbesondere wenn das Ergebnis in einem
"Graubereich" liegt.
Physiologische / medizinische Messwerte sind mit einer gewissen Unsicherheit behaftet. Diese
hat mehrere Ursachen. Die Ausprägung (der Messwert)
eines Merkmals bei einem Merkmalsträger (Proband,
Patient) hängt von der Art des Merkmals ab:

qualitativ (ohne zahlenmäßige Ordnung, z.B. jung / alt, männlich / weiblich) oder

quantitativ; ein quantitatives Merkmal ist
 diskret
diskret (Wertebereich: natürliche
Zahlen, z.B. Leukozytenzahl) oder
stetig (Wertebereich: reelle Zahlen,
d.h. auf einer kontinuierlichen Skala liegend, z.B. Betrag des
Blutdrucks).
Je nach Art des Merkmals differiert die Darstellung einer
Verteilung, und werden unterschiedliche statistische Verfahren
angewendet.
Biometrie (Biostatistik)
Biometrie (gr. 'Lebensmessung')
bzw. Biostatistik kann als die Anwendung statistischer Methoden auf die Lösung
biologischer Probleme verstanden werden. Biomathematik setzt die
Werkzeuge der Statistik und Mathematik für die Lösung
medizinischer Fragestellungen oder die Beschreibung medizinischer
Phänomene ein.
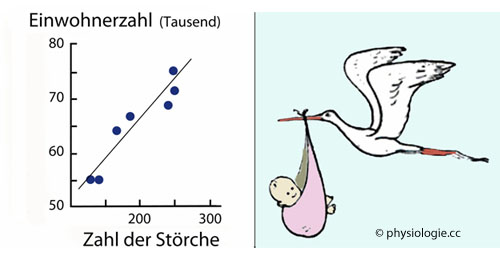
 Abbildung: Korrelation bedeutet nicht notwendigerweise Kausalität (Verursachung)
Abbildung: Korrelation bedeutet nicht notwendigerweise Kausalität (Verursachung)
Nach einer Vorlage bei Richard Mould, Introductory Medical Statistics (CRC Press)
Die
Bevölkerungszahl der Einwohner von Oldenburg zu Ende der Jahre 1930 bis
1936 ist als Funktion der in diesen Zeiträumen beobachteten Anzahl der
Störche dargestellt.
Die Korrelation beweist offensichtlich nicht, dass Störche
Kinder bringen  . Sie kann aus Zufall oder willkürlicher Auswahl von Datenpunkten resultieren, oder auf einer gemeinsamen (dahinterliegenden) Ursache beruhen, die beide Zustandsvariablen unabhängig voneinander beeinflusst
. Sie kann aus Zufall oder willkürlicher Auswahl von Datenpunkten resultieren, oder auf einer gemeinsamen (dahinterliegenden) Ursache beruhen, die beide Zustandsvariablen unabhängig voneinander beeinflusst

Wesentlich für die Interpretation einer Korrelation ist ihre Plausibilität.
Eine Koinzidenz (Assoziation) von Ereignissen - ein zeitliches oder
räumliches Zusammentreffen - bedeutet nicht unbedingt, dass ein
(zumindest direkter) kausaler (ursächlicher) Zusammenhang zwischen
ihnen besteht. Eine Koinzinenz kann auch dadurch vorgetäuscht werden,
dass Datenpunkte aus einem größeren Datenpool willkürlich so ausgewählt
wurden, dass mittels des manipulierten Datensatzes eine "signifikante"
Korrelation errechnet werden kann (betrügerische Absicht).
 Das Vorliegen einer Korrelation kann eine direkte Ursache nahelegen, muss es aber nicht ( wie in der obigen Abbildung anhand eines grotesken Beispiels gezeigt - unabhängig, wie "signifikant" der Wahrscheinlichkeitswert der Korrelation ist).
Das Vorliegen einer Korrelation kann eine direkte Ursache nahelegen, muss es aber nicht ( wie in der obigen Abbildung anhand eines grotesken Beispiels gezeigt - unabhängig, wie "signifikant" der Wahrscheinlichkeitswert der Korrelation ist).
 Beschreibende
Beschreibende
(
deskriptive) Statistik - sie vermittelt Verfahren zur übersichtlichen
Darstellung von Untersuchungsergebnissen, wie
Mittelwert und Streumaße, z.B. die
Varianz:

Diese quantifiziert, wie breit die Streuung der Einzelwerte einer
entsprechenden Größe in einer Gruppe ist (z.B. die Verteilung des
Körpergewichts der Schüler einer Klasse);
Erkundende (
explorative) Statistik - sie versucht, Daten, über deren Struktur wenig bekannt ist, sinnvoll darzustellen;
Schließende
(
induktive) Statistik - sie bietet Schätz- und Testverfahren,
ermöglicht die Prüfung von Hypothesen durch statistische Tests.
Annahmen können bei geringer Wahrscheinlichkeit für ihre Gültigkeit als
widerlegt gelten (Falsifizierung:
Statt einer vorgeschlagenen Hypothese nimmt man im Fall ihrer
Widerlegung eine als besser geeignet erscheinende Antithese an).
Beschreibende (deskriptive) Statistik
 Deskriptive
Statistik gibt Hinweise auf Kennwerte einer Datengruppe. Diese liegt um
eine "Mitte" der Verteilung (Mittelwert, Modalwert, Medianwert u.a.)
und hat eine bestimmte Bandbreite - charakterisiert z.B. durch Minimal-
und Maximalwert, Perzentilen, Varianz oder Standardabweichung.
Deskriptive
Statistik gibt Hinweise auf Kennwerte einer Datengruppe. Diese liegt um
eine "Mitte" der Verteilung (Mittelwert, Modalwert, Medianwert u.a.)
und hat eine bestimmte Bandbreite - charakterisiert z.B. durch Minimal-
und Maximalwert, Perzentilen, Varianz oder Standardabweichung.
Mittels beschreibender
Statistik (descriptive statistics) wird
die Art der Verteilung ermittelter Datenpunkte beschrieben. Die
gesammelten Daten werden geordnet, als Tabellen oder Grafiken
dargestellt und durch Kennzahlen zusammengefasst - etwa als Lokalisationsmaße (z.B. Mittelwerte) und Dispersionsmaße (z.B. Streubereiche).
Bezüglich der "Schwerpunkte" von Verteilungen unterscheidet man Mittel-, Median- und Modalwerte (Abbildung), um die herum die einzelnen Beobachtungswerte zu liegen kommen (s. weiter unten):

Abbildung: Mittel-, Median- und Modalwert einer Verteilung
In diesem Beispiel liegt eine
asymmetrische Verteilung (hier: mit positiver skewness) vor.
 Der Modalwert ist der am häufigsten vorkommende Wert in der
Stichprobe, der Medianwert teilt die Stichprobe in zwei gleich große
Hälften, und der (arithmetische) Mittelwert gibt den durchschnittlichen Messwert (Summe der Messwerte / Zahl der Beobachtungen) an.
Bei einer perfekten Normalverteilung, die durch eine symmetrische
Wahrscheinlichkeitsdichteverteilung gekennzeichnet ist
("Glockenkurve"), fallen Mittelwert und Medianwert zusammen. In der Praxis ist kaum der
Fall, und jede Angabe hat ihren Vor- / Nachteil: Sehr häufug wird der Mittelwert
angegeben, dessen Betrag aber von allfälligen Ausreißern stark
beeinflusst wird. Weniger empfindlich gegenüber Ausreißern ist der Medianwert. Den Modalwert anzugeben ist nur bei hoher Fallzahl sinnvoll, da sein Betrag sonst zu stark zufallsa
Der Modalwert ist der am häufigsten vorkommende Wert in der
Stichprobe, der Medianwert teilt die Stichprobe in zwei gleich große
Hälften, und der (arithmetische) Mittelwert gibt den durchschnittlichen Messwert (Summe der Messwerte / Zahl der Beobachtungen) an.
Bei einer perfekten Normalverteilung, die durch eine symmetrische
Wahrscheinlichkeitsdichteverteilung gekennzeichnet ist
("Glockenkurve"), fallen Mittelwert und Medianwert zusammen. In der Praxis ist kaum der
Fall, und jede Angabe hat ihren Vor- / Nachteil: Sehr häufug wird der Mittelwert
angegeben, dessen Betrag aber von allfälligen Ausreißern stark
beeinflusst wird. Weniger empfindlich gegenüber Ausreißern ist der Medianwert. Den Modalwert anzugeben ist nur bei hoher Fallzahl sinnvoll, da sein Betrag sonst zu stark zufallsabhängig ist
AMW = (E1 + E2 ... + EN) / N
|
Der Mittelwert liegt in der Mitte (beim häufigsten Wert) einer Normalverteilung (Gauß-sche Glockenkurve). Teilt der errechnete Mittelwert die Verteilung nicht in zwei gleich große Hälften, liegt keine Normalverteilung vor.
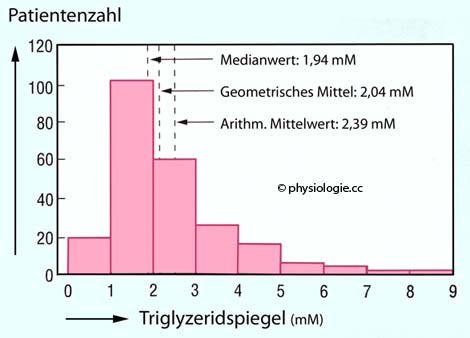
 Abbildung: Vergleich von Mittelwerten bei einer asymmetrischen Datenverteilung
Abbildung: Vergleich von Mittelwerten bei einer asymmetrischen Datenverteilung
Nach
einer Vorlage in Petrie / Sabin, Medical Statistics at a Glance. Blackwell Science 2000
In
einer Stichprobe von 232 Männern, die an einer Herzerkrankung litten,
wurde der Serum-Triglyzeridspiegel ermittelt. Die Resultate waren
"rechtslastig", nicht normalverteilt. Die arithmetrische Mitte gab
einen höheren "Mittelwert" an als der Medianwert und das geometrische
Mittel, letzteres repräsentierte in diesem Beispiel den "Mittelpunkt"
der Verteilung besser als der durchschnittliche Messwert
Ist eine Verteilung nicht symmetrisch, reduziert sich die Sinnhaftigkeit der Angabe des Mittelwertes. Hier kann die Ermittlung des geometrischen Mittels helfen ( Abbildung):
Ist die Datenverteilung nach rechts geneigt, werden die Einzelwerte
logarithmiert (Logarithmus = Hochzahl). Im Idealfall sind die
Hochzahlen (im Gegensatz zu den Messwerten per se) normalverteilt. Der
mittlere Logarithmus wird anschließend delogarithmiert (damit dieselben
Einheiten wie bei der Originalverteilung verwendet werden können), und
dieser Betrag ist das geometrische Mittel - dieses sollte dann nahe am
Medianwert (s. unten) liegen (und einen geringeren Betrag aufweisen als
der Mittelwert der Rohdaten).
"Ausreißer" mit von der Gruppe stark abweichenden
Messwerten können den Mittelwert deutlich verrücken. Beispielsweise
steigert eine 90-jährige Person in einer kleinen Gruppe von Jugendlichen das durchschnittliche Alter deutlich, der
Mittelwert ist nicht mehr repräsentativ für die Gruppe.
In solchen Fällen einer asymmetrischen Verteilung ist der Medianwert
besser zur Charakterisierung der betreffenden Eigenschaftsverteilung im Kollektiv
geeignet. Es ist der Wert, der die "oberen" 50% von den "unteren" 50%
der Verteilung trennt:
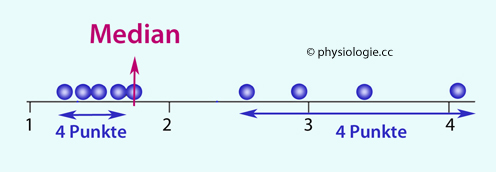
Abbildung: Medianwert
In diesem Beispiel liegen 4 Meßpunkte (von insgesamt 9) und 4 überunter dem Median (in diesem Fall ~1,7, das ist der
Wert des 5. Meßpunktes der Reihe). Ist die Zahl der Beobachtungen
geradzahlig, ist der Medianwert definiert als der Mittelwert zwischen
den beiden mittleren Messpunkten
Bezüglich der Streubereiche stellt man die Häufigkeitsverteilung der Messwerte einer Gruppe von Beobachtungen (einer repräsentativen Stichprobe. sample - Teil der Grundgesamtheit) entlang der betreffenden Größenachse (Streuung) dar. Die aus einer Stichprobe gewonnenen Kennzahlen lassen dann Rückschlüsse auf die Grundgesamtheit zu.
Ein ermittelter Streubereich der Einzelbeobachtungen (z.B. Körpergröße,
Körpergewicht, Blutdruck...) kann unterschiedlich charakterisiert
werden, z.B. als Spannweite oder Variationsbreite (range) - von kleinstem bis größtem Wert, mit dem Nachteil, von Ausreissern stark beeinflusst zu werden.
Als Varianz bezeichnet man das
durchschnittliche Abweichungsquadrat, definiert als die Summe aller
Abweichungsquadrate dividiert durch (Zahl aller Messwerte -1). Das
entspricht dem unter der Wurzel stehenden Term für die Standardabweichung:
Die Standardabweichung (standard deviation SD) ist definiert als die Quadratwurzel aus der Varianz um den Mittelwert:
Dabei
bedeutet X den Wert einer Einzelmessung, X-quer den arithmetischen
Mittelwert aus allen Beobachtungen, n die Zahl der Beobachtungen; der
unter der Wurzel angegebene Term (Summe aller Abweichungsquadrate / Zahl aller Messwerte -1) ist die Varianz. Wichtig ist die Bedeutung dieses Streumaßes:
 Die Standardabweichung sagt aus, wie stark in einem Kollektiv mit normalverteilten Daten die Werte einzelner Beobachtungen um den Mittelwert streuen. Dabei haben Ausreißer nur eine geringe Auswirkung auf den SD-Bereich.
Die Standardabweichung sagt aus, wie stark in einem Kollektiv mit normalverteilten Daten die Werte einzelner Beobachtungen um den Mittelwert streuen. Dabei haben Ausreißer nur eine geringe Auswirkung auf den SD-Bereich.
Der Vorteil der Standardabweichung als Streumaß ist ihre anschauliche
Bedeutung: Der Anteil der in einem bestimmten SD-Bereich liegenden
Beobachtungen lässt sich quantifizieren als
 68,2% der Gesamtheit der Beobachtungen im Bereich ±1 SD um den Mittelwert,
68,2% der Gesamtheit der Beobachtungen im Bereich ±1 SD um den Mittelwert,
95,4% der Gesamtheit der Beobachtungen im Bereich ±2 SD um den Mittelwert,
99,7% der Gesamtheit der Beobachtungen im Bereich ±3 SD um den Mittelwert
( vgl. unten).
vgl. unten).
Der Nachteil der Angabe der Streuung als SD ist, dass sie - streng genommen - nur für Normalverteilungen
der Datenpunkte gilt. Ihre Anwendbarkeit nimmt in dem Maße ab, in dem
die Verteilung nicht normalverteilt ist (es gibt andere Möglichkeiten
zur
Charakterisierung der Streuweite, s. weiter unten).
Als Variationskoeffizient (Variabilitätskoeffizient, coefficient of variation CV) bezeichnet man das Verhältnis des Betrags der Standardabweichung (SD) zum Betrag des Mittelwerts µ, also
oder
als prozentuellen Anteil 100 (SD / µ). Hier ist der Vorteil die
Unabhängigkeit dieser Größe von der jeweils gewählten Einheit - der
Betrag des Variationskoeffizienten bleibt auch bei Wechsel der für die
Größenangabe der (rationalskalierten) Variablen verwendeten Einheit
unverändert.
Der Medianwert bildet den Mittelpunkt sogenannter Box-Whisker-Plots ("Kastengraphik"). Diese kennzeichnen die Verteilung von Messpunkten (Streuung und Lage) in Form eins zentralen Kästchens (box) und der Bereichsangabe zwischen zwei "Antennen" (whiskers), die ein "Minimum" und ein "Maximum" angeben:
 Abbildung: Box and whisker plot
Abbildung: Box and whisker plot
Um den Medianwert liegen jeweils die Hälfte
aller Beobachtungen. Q1 kennzeichnet die 25%-Perzentile, Beobachtungen
mit niedrigeren Beträgen des Messwertes machen ein Viertel aller
Beobachtungen aus. Q3 kennzeichnet die 75%-Perzentile, Beobachtungen
mit höheren
Beträgen des Messwertes machen ebenfalls ein Viertel aller
Beobachtungen aus.
Der Interquartilsabstand IQA (inter-quartile range IQR)
- auch Quartilsabstand genannt - liegt zwischen Q1 und Q3. Die Lage des "Minimums" und des "Maximums"
wird verschieden definiert, bei symmetrischen Verteilungen z.B. durch
einen Abstand von 1,5 IQR unterhalb bzw. oberhalb des Betrages von Q1
bzw. Q3.
Messpunkte, die außerhalb des Bereichs zwischen "Minimum" und "Maximum" liegen, werden als "Ausreißer" individuell dargestellt
Box
and whisker-Plots stellen sowohl normalverteilte als auch
nicht-normalverteilte Streuungen von Messergebnissen übersichtlich dar.
Die Strecke zwischen der 25. und 75. Perzentile heißt Quartilsabstand (interquartile range) und
enthält die Hälfte
aller Beobachtungen - also den Bereich mit den mittleren 50% der Werte,
die im Sample ermittelt wurden. Dieser Wert ist leicht zu ermitteln und
wird von Ausreissern so gut wie nicht beeinflusst.
Wie weit der untere und der obere Whisker reicht,
hängt einerseits von der Art der Verteilung, andererseits von der
Definition ab, mit der die Begrenzung festgelegt wird (z.B.
2,5-%-Quantil und 97,5-%-Quantil, der Whisker-Bereich umspannt dann 95%
aller Beobachtungen). Als Ausreißer bezeichnet man individuell
darzustellende Messpunlte, die außerhalb des Antennenbereichs zu liegen
kommen. Man unterscheidet manchmal auch zwischen "milden" und
"extremen" Ausreißern, die dann unterschiedlich darzustellen sind.
 Vieles in der Medizin wird in Prozent (Hundertstel) angegeben. Dabei ist es wesentlich, immer die Frage zu stellen, % wovon (100% = 1), d.h. die Gesamtheit von etwas - dieses Etwas muss definiert werden.
Vieles in der Medizin wird in Prozent (Hundertstel) angegeben. Dabei ist es wesentlich, immer die Frage zu stellen, % wovon (100% = 1), d.h. die Gesamtheit von etwas - dieses Etwas muss definiert werden.
 Eine Prozentzahl ohne Kenntnis / Angabe der Gesamtheit (=1) ist sinnlos
Eine Prozentzahl ohne Kenntnis / Angabe der Gesamtheit (=1) ist sinnlos
Beispiel: Wie groß bist Du? Antwort: 110 Prozent 
Prozentwerte können irreführend sein: Wird z.B. gesagt, eine Partei
habe 20% Stimmen dazugewonnen, kann das viel sein - etwa wenn 1
die Gesamtheit aller Wähler bedeutet - oder wenig, wenn mit "1" eine kleine Teilmenge gemeint ist, etwa die Anhänger einer Minipartei.
Explorative Statistik stellt u.a. Zusammenhänge
von Merkmalen und Einflussgrößen dar - z.B., wie verhält sich die Tageszeit zu Ihrer Laune? Darstellbar ist dies mittels einer Regressionsanalyse (=Analyseverfahren, das die Beziehung mehrerer Variablen modelliert).
Dabei werden Daten im Konnex dargestellt, ohne noch eine abschließende Interpretation
zu geben (das ist Aufgabe der schließenden, nicht der beschreibenden Statistik).
Genauigkeit
Zum Begriff der "Genauigkeit" ist zu unterscheiden zwischen
Absolutgenauigkeit (accuracy): Sie sagt aus, wie nahe der Durchschnittswert am wahren Wert liegt - d.h. wie richtig das durchschnittliche Resultat des Messverfahrens ist.
Statistisch ist dies beschreibbar als die Differenz zwischen dem
"Referenzwert" (wahren Wert) und dem Mittelwert der Messergebnisse;
Präzision (precision): Sie sagt aus, wie gering die Streuung ist -
d.h. wie verlässlich das Resultat bei wiederholter Messung wiederkehrt
(statistisch beschreibbar, z.B. als Normalverteilung wie in der
Abbildung). Die Präzision ist über eine Verteilungsbeschreibung
quantifizierbar (z.B. wie groß ist die Standardabweichung einer
Normalverteilung der Messergebnisse)?
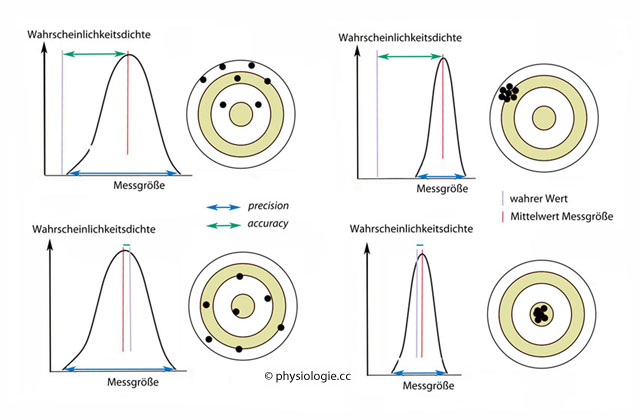
Abbildung: Absolutgenauigkeit und Präzision
Absolutgenauigkeit
bedeutet, wie nahe der Mittelwert der Verteilung der Werte aus einer
Messreihe am wahren Wert der Zustandsgröße liegt - je geringer die
Differenz, desto höher die Genauigkeit.
Präzision bedeutet, wie nahe
die Ergebnisse einer Messreihe am Mittelwert der Verteilung liegen - je
geringer die Streuung, desto höher die Präzision.
Links oben: Geringe Genauigkeit, geringe Präzision
Rechts oben: Geringe Genauigkeit, hohe Präzision
Links unten: Hohe Genauigkeit, geringe Präzision
Rechts unten: Hohe Genauigkeit und Präzision
 So
kann eine Waage immer wieder einen falschen Absolutwert angeben; dann
ist die Präzision möglicherweise hoch ("immer genau daneben"), die Absolutgenauigkeit aber
gering (Abweichung vom wahren Wert).
So
kann eine Waage immer wieder einen falschen Absolutwert angeben; dann
ist die Präzision möglicherweise hoch ("immer genau daneben"), die Absolutgenauigkeit aber
gering (Abweichung vom wahren Wert).
 Sie
kann aber auch umgekehrt im Schnitt den wahren Wert anzeigen, nur die
Einzelmessungen streuen stark - breite Verteilung; hohe
Absolutgenauigkeit, geringe Präzision; wiederholte Messungen ergeben im Schnitt das richtige Resultat.
Sie
kann aber auch umgekehrt im Schnitt den wahren Wert anzeigen, nur die
Einzelmessungen streuen stark - breite Verteilung; hohe
Absolutgenauigkeit, geringe Präzision; wiederholte Messungen ergeben im Schnitt das richtige Resultat.
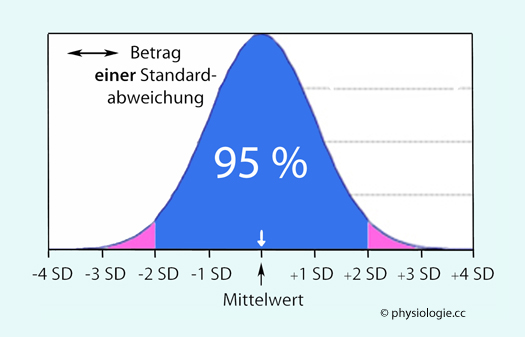
Abbildung: Häufigkeits-Verteilungskurve (Gauß'sche Glockenkurve)
Normalverteilung, Mittelwert (Pfeil), Abstand vom Mittelwert in Beträgen der Standardabweichung (SD, standard deviation).
Der einfache Standardabweichungsbereich um den Mittelwert (Bereich zwischen -1 SD und +1 SD) beinhaltet 68,2%
Der doppelte Standardabweichungsbereich (-2 SD bis +2 SD) 95,4%
Der dreifache Standardabweichungsbereich (-3 SD bis +3 SD) 99,7% der Beobachtungen in der Verteilung
Bei einer symmetrischen, d.h. Normalverteilung (Gauß-Verteilung, normal distribution)
- eine eingipflige, stetige Verteilung, deren Form durch den Mittelwert
und die Varianz der Messergebnisse vollständig definiert ist -
überstreicht der Bereich, der von 2 Standardabweichungen unter dem Mittelwert bis zu 2 Standardabweichungen über dem Mittelwert
liegt, 95,4% aller in dieser Verteilung beobachteten Werte (blauer
Bereich in der Abbildung).
Als Referenzbereich bezeichnet
man einen definierten Bereich um einen Mittelwert (MW), in dem ein
dementsprechend großer Anteil aller Messwerte liegt. Legt man z.B. die
Spanne der doppelten Standardabweichung (2 SD) um den Mittelwert (MW -2
SD bis MW + 2 SD) fest, liegen ~95% der Beobachtungen in diesem
Referenzbereich. Jeweils ~2,5% der Beobachtungen fallen dann aus dem Referenzbereich
heraus, sie liegen vom Mittelwert weiter als zwei Standardabweichungen entfernt (violette Bereiche in der Abbildung).
Liegt ein Ergenis außerhalb des
Referenzbereichs (Wahrscheinlichzkeit 5%), bedeutet das nicht
automatisch, dass z.B. ein Patient - von dem der Befund stammt - als
klinisch krank einzustufen ist; es bedeutet lediglich, dass das
Ergebnis statistisch in einem 5%-Wahrscheinlichkeitsbereich liegt (der
Patien kann vollkommen gesund sein). Zahlreiche Faktoren können einen Einfluss auf das Ergebnis haben (Probengewinnung,
Messmethode, Alter und Geschlecht der Probanden etc). Messergebnisse
sind Indikatoren, die Hinweise, aber keine 100%-ige diagnostische
Sicherheit geben.
Das Konfidenzintervall (confidence interval) gibt an, in welchem Bereich der Mittelwert der gesamten Population liegt, auf die man sich bezieht.
Ein Beispiel: 100 hypertensiven
Patienten wird ein Medikament verabreicht, der Mittelwert des
systolischen Blutdrucks sinkt um 20 mmHg, mit einem
95%-Konfidenzintervall zwischeen 15 und 25%. Man kann zu 95% sicher
sein, dass der Effekt in dieser Spanne liegt. Wäre das
Konfidenzintervall größer - z.B. bei nur 50 Patienten von -5% bis +45%
-, ist die Wahrscheinlichkeit, dass in Wirklichkeit keine Wirkung erfolgt ist, zu groß (>5%), um eine tatsächliche Wirkung vermuten zu können.
 Je größer die Stichprobe (sample)
- also der Anteil an der gesamten Population, an der ein Effekt
bestimmt werden soll -, desto kleiner ist meist die Spanne des
Konfidenzintervalls.
Je größer die Stichprobe (sample)
- also der Anteil an der gesamten Population, an der ein Effekt
bestimmt werden soll -, desto kleiner ist meist die Spanne des
Konfidenzintervalls.
Was ist der Unterschied zwischen der Standardabweichung und dem Konfidenzintervall? Die Standardabweichung gibt Aufschluß über die Streuung der Einzelwerte in einer Stichprobe; das Konfidenzintervall gibt an, in welchen den Bereich der "wahre" Mittelwert (wenn man die gesamte Population untersuchen könnte) wahrscheinlich zu liegen kommt.
Klinische Messwerte, die innerhalb des doppelten
Standardabweichungsbereichs um den "idealen" Wert liegen, werden im allgemeinen als
"unauffällig" gewertet ("negativer Befund"). Fällt ein Messwert aus
diesem Bereich heraus, gilt er als "auffällig" ("positiver Befund").
Das bedeutet nicht, dass der Lieferant eines "negativen"
Befundes mit Sicherheit "gesund" und derjenige eines "positiven"
Befundes automatisch "krank" ist (Fehler sind von der Probengewinnung
über das Transport- und Messprozedere bis zur Dateninterpretation
möglich, und es gibt biologische Besonderheiten).
Außerdem sind die
Referezbereiche oft abhängig von Alter und Geschlecht.
Tatsächlich werden meist mehrere Kriterien für die Beurteilung des
Gesundheits- bzw. Erkrankungszustands der betroffenen Person
herangezogen.
Physiologische ("unauffällige") Messwertbereiche bedeuten nicht immer die
doppelte Standardabweichung um den Mittelwert. Richtwertgrenzen
orientieren sich oft an klinischer Erfahrung, sie können im Rahmen von Consensus-Konferenzen festgelegt werden.
Weiters muss berücksichtigt werden, dass Messergebnisse methoden- und laborabhängig sind (und damit die Referenzbereiche). Und: Literaturangaben sind uneinheitlich, oft auch unklar.

 Klinische Laborwerte wurden in dieser Website aus verschiedenen Quellen zusammengeführt. Als primäre Datenquelle diente das Lexikon der Medizinischen Laboratoriumsdiagnostik (Gressner / Arndt, 3. Aufl. 2019, Springer-Verlag).
Klinische Laborwerte wurden in dieser Website aus verschiedenen Quellen zusammengeführt. Als primäre Datenquelle diente das Lexikon der Medizinischen Laboratoriumsdiagnostik (Gressner / Arndt, 3. Aufl. 2019, Springer-Verlag).
Schließende (induktive) Statistik
Methoden zur Datenanalyse dienen einerseits der Formulierung, andererseits der Verifizierung von Hypothesen. Die schließende
Statistik (statistical inference) rechnet Wahrscheinlichkeiten
aus, mit denen vermutete Sachverhalte (z.B. über einen
Kausalzusammenhang) zutreffen (oder nicht zutreffen).
 Biometrische Testverfahren sollen Hypothesen
(vermutete Sachverhalte) anhand von Versuchsergebnissen überprüfen und gegenüber
möglicherweise irreleitenden Zufallseffekten absichern. Man erhebt Daten (durch Messung / Beobachtung gewonnene Werte oder Befunde) an Zufallsstichproben (random samples), das sind Teile des gesamten Kollektivs (an Datenträgern), die mit Hilfe spezieller Auswahlverfahren zur Datenerhebung ausgesucht werden. Die statistische Auswertung von Zufallsstichproben ist ein heuristisches Verfahren (Heuristik ist die Methode, mit begrenztem Wissen bzw. unvollständigen Informationen zu wahrscheinlichen Aussagen zu gelangen).
Biometrische Testverfahren sollen Hypothesen
(vermutete Sachverhalte) anhand von Versuchsergebnissen überprüfen und gegenüber
möglicherweise irreleitenden Zufallseffekten absichern. Man erhebt Daten (durch Messung / Beobachtung gewonnene Werte oder Befunde) an Zufallsstichproben (random samples), das sind Teile des gesamten Kollektivs (an Datenträgern), die mit Hilfe spezieller Auswahlverfahren zur Datenerhebung ausgesucht werden. Die statistische Auswertung von Zufallsstichproben ist ein heuristisches Verfahren (Heuristik ist die Methode, mit begrenztem Wissen bzw. unvollständigen Informationen zu wahrscheinlichen Aussagen zu gelangen).
In
komplexen Systemen (wie meistens im medizinischen Bereich) interagieren
zahlreiche Größen, klare Ursachen-Wirkungs-Beziehungen sind oft schwer erkennbar, die Reduktion auf nur eine Einflussvariable
unmöglich.
Prinzipien der
Statistik, der physiologische Gesamtzusammenhang, und individuelle
Komponenten müssen in jedem Einzelfall Berücksichtigung finden.
Theorien
bauen
auf Hypothesen auf; auch sie sind spekulativ, aber allgemeiner
gehalten als (die ihnen zugrundeliegenden) Hypothesen, die (jede für
sich) wissenschaftlich getestet werden können. Es gibt mehrere
Möglichkeiten, den Begriff "Theorie" zu definieren; in den
Naturwissenschaften versteht man darunter eine Form des rationalen
Umgangs mit Phänomenen, die in der Natur zu beobachten oder zu
erschließen sind, wobei naturwissenschaftliche Methoden und Verfahren
angewendet werden (empirische Bestätigung getroffener Annahmen,
prädiktive Potenz der Theorie etc.).
 Resultat
eines statistischen Schlusses ist nicht Gewissheit (Sicherheit), sondern eine bestimmte Wahrscheinlichkeit (probability),
mit der z.B. ein Unterschied zwischen den geprüften Stichproben
(z.B. je 20 Patienten) in Bezug auf die geprüfte Einflussgröße tatsächlich besteht. Eine getroffene
Aussage (z.B. ob Kopfschmerz nach Gabe von Aspirin rascher
abklingt als bei Verwendung eines Placebo) wird als mehr oder weniger wahrscheinlich gewertet.
Resultat
eines statistischen Schlusses ist nicht Gewissheit (Sicherheit), sondern eine bestimmte Wahrscheinlichkeit (probability),
mit der z.B. ein Unterschied zwischen den geprüften Stichproben
(z.B. je 20 Patienten) in Bezug auf die geprüfte Einflussgröße tatsächlich besteht. Eine getroffene
Aussage (z.B. ob Kopfschmerz nach Gabe von Aspirin rascher
abklingt als bei Verwendung eines Placebo) wird als mehr oder weniger wahrscheinlich gewertet.

Abbildung: Zustands-Zeitverlauf - natürlich, mit Placebo, mit Verum (hypothetisch, vereinfacht)
In dieser Darstellung weist eine Verbesserung des klinischen Zustandes nach oben, eine Verschlechterung nach unten.
Beispiel Kopfschmerz: Dieser klingt nach einiger Zeit oft von selbst ab (natürlicher Verlauf). Der Zustand kann sich während des Beobachtungszeitraums auch verschlechtern, die Kurve zeigt dann nach unten.
Verlauf mit Placebo: Durch Anbieten eines Placebo - woran sich bestimmte Hoffnungen / Erwartungen knüpfen und endogene Mechanismen aktiviert werden, z.B. Schmerzhemmung in Frontalhirn, limbischem System u.a., vgl. dort - tritt Erholung rascher auf.
Verlauf mit Verum: Direkte
(molekularbiologische) Effekte eines geeigneten Pharmakons bewirken -
zusätzlich zum "Placebo-Effekt" - weitere Beschleunigung der
Schmerzdämpfung.
Das
Ausmaß dieser drei Effekte zum Schluss der Beobachtungsphase:
Physiologische Normalisierung blau, Placebo-Wirkung (psycho-biologischer Effekt) grün,
Medikamentenwirkung (drug effect) rot. Manchmal können Pharmaka den Verlauf auch negativ beeinflussen (strichlierte Kurve unter der ausgezogenen), dann würden sie wohl als Gift gewertet werden
 Immer
bleibt in solchen Fällen eine
Restwahrscheinlichkeit, dass eine getroffene Schlussfolgerung (z.B. ein
getestetes Medikament reduziert Schmerzen in Dauer oder Intensität)
unzutreffend ist.
(Dabei ist es durchaus möglich, dass nicht das Medikament an sich,
sondern seine Einnahme einen schmerzlindernden Effekt hat - Placebo-Wirkung).
Immer
bleibt in solchen Fällen eine
Restwahrscheinlichkeit, dass eine getroffene Schlussfolgerung (z.B. ein
getestetes Medikament reduziert Schmerzen in Dauer oder Intensität)
unzutreffend ist.
(Dabei ist es durchaus möglich, dass nicht das Medikament an sich,
sondern seine Einnahme einen schmerzlindernden Effekt hat - Placebo-Wirkung).
 Was ist der p-Wert? "p" kommt von probability, es handelt sich also um ein Wahrscheinlchkeitsmaß
- ein sehr wichtiges Konzept (Wahrscheinlichkeitstheorie = Stochastik ). Der p-Wert gibt an, mit welcher
Wahrscheinlichkeit ein beobachteter Unterschied zwischen zwei
verglichenen Kollektiven nur zufällig aufgetreten ist (Sicherheit:
p=1,0; Unmöglichkeit: p=0,0).
Was ist der p-Wert? "p" kommt von probability, es handelt sich also um ein Wahrscheinlchkeitsmaß
- ein sehr wichtiges Konzept (Wahrscheinlichkeitstheorie = Stochastik ). Der p-Wert gibt an, mit welcher
Wahrscheinlichkeit ein beobachteter Unterschied zwischen zwei
verglichenen Kollektiven nur zufällig aufgetreten ist (Sicherheit:
p=1,0; Unmöglichkeit: p=0,0).
Liegt der p-Wert z.B. bei 0,05, heißt das, dass der Effekt in einem von 20 Untersuchungen (5%) durch Zufall auftreten würde. Wenn die Wahrscheinlichkeit der
Nullhypothese unter 5% (p<0,05) liegt, wird meist ein Unterschied
(Effekt des Medikaments) angenommen - das Ergebnis wird als signifikant betrachtet (Beispiel: man vermutet, Aspirin ist wirkungsvoller als
Placebo).
Die Wahl dieses 'Schwellenwerts' ist eine willkürliche Konvention; je
niedriger der p-Wert, desto überzeugender (wahrscheinlicher richtig)
ist jedenfalls das Ergebnis. Die Schwelle zu "hoher Signifikanz" wird
bei p=0,01 (1%), diejenige zu "sehr hoher Signifikanz" bei 0,001 (0,1%)
angenommen. Auch bei hoher Signifikanz ist es immer noch möglich, dass
ein Effekt nur zufällig aufgetreten ist, aber die Wahrscheinlichkeit
ist dann sehr gering, dass das wirklich der Fall ist.
Eine (allenfalls zu falsifizierende) Nullhypothese
(null hypothesis) ist die Vermutung, dass zwischen zwei zu
vergleichenden Stichproben (=Teile der Gesamtheit; dies könnten z.B. alle Kopfschmerzpatienten auf der Welt sein) kein
Unterschied (z.B. bezüglich der Kopfschmerzdauer) besteht. Die
Wahrscheinlichkeit, dass diese Vermutung zutrifft, ist umso kleiner,
je wahrscheinlicher ein Unterschied - in Bezug auf die getestete Variable - zwischen den beiden Stichproben (z.B. Aspirin vs. Placebo ) ist.
Will man also die Wirkung einer Maßnahme als wahrscheinlich darstellen,
geht es darum, die Nullhypothese mit ausreichender Wahrscheinlichkeit
zurückweisen zu können (to reject the null hypothesis) - Sicherheit (p=0) gibt es dabei nicht.
 Relevanz: Ob der Effekt auch relevant
ist, muss unabhängig davon entschieden
werden; da kommt es auf den Zusammenhang an. Es ist möglich, dass ein signifikantes Ergebnis dennoch
irrelevant ist, z.B. weil der Effekt zu gering ausfällt - z.B. eine
Blutdrucksenkung um 1% - oder weil die Frage der Untersuchung falsch gestellt wurde.
Relevanz: Ob der Effekt auch relevant
ist, muss unabhängig davon entschieden
werden; da kommt es auf den Zusammenhang an. Es ist möglich, dass ein signifikantes Ergebnis dennoch
irrelevant ist, z.B. weil der Effekt zu gering ausfällt - z.B. eine
Blutdrucksenkung um 1% - oder weil die Frage der Untersuchung falsch gestellt wurde.
Wie überprüft man (begründete) Vermutungen?
Wahrheitsgehalt von Hypothesen, Fehler 1. und 2. Art, Spezifität und Sensitivität
Statistische Tests geben an, wie wahrscheinlich
ein vermuteter Sachverhalt zutrifft bzw. eine Nullhypothese zurückgewiesen
werden kann. Solche Überlegungen treffen auch auf die Beschreibung der
Güte diagnostischer Tests zu. Es können zwei Arten von Fehlern
unterlaufen:

Abbildung: Überschneidung der Verteilungskurven der Ausprägung eines Merkmals in zwei Populationen
Zwei Gruppen, die sich hinsichtlich eines bestimmten Messwertes (z.B. Blutdruck) möglicherweise unterscheiden. Das Merkmal ist innerhalb der Testgruppen normalverteilt.
Ordinate: Häufigkeit; Abszisse: Betrag des Messwertes (z.B. kPa).
Die Power (Stärke)
eines Tests sagt aus, wie wahrscheinlich ein bestehender Unterschied
zwischen zwei Gruppen (die bezüglich des Testwertes verschieden sind)
tatsächlich
erkannt wird. Sie beträgt 1 minus dem Betrag des Beta-Fehlers (s.
unten).
Je
größer die Power, desto geringer die Wahrscheinlichkeit eines
ß-Fehlers (dass z.B. ein wirksames Medikament irrtümlich als
unwirksam eingestuft wird)
Fehler 1. Art
α-Fehler, type I error: Die Merkmalsverteilung der Stichproben kann dazu veranlassen, die
Nullhypothese zu verwerfen, obwohl sie in Wirklichkeit
richtig ist (z.B. wird vermutet, dass ein Medikament wirksam ist, obwohl die beiden Testgruppen sich
in Wahrheit nicht unterscheiden).
Die Höhe dieser Irrtumswahrscheinlichkeit nennt man das α-Risiko (Signifikanzniveau α).

 Man sagt auch, die Entscheidung
ist bei Vorliegen eines α-Fehlers falsch positiv.
Auf eine medizinische Diagnose bezogen, heißt das: man geht
von einem positiven Befund aus (Vermutung: Person krank), obwohl
dies unzutreffend ist.
Man sagt auch, die Entscheidung
ist bei Vorliegen eines α-Fehlers falsch positiv.
Auf eine medizinische Diagnose bezogen, heißt das: man geht
von einem positiven Befund aus (Vermutung: Person krank), obwohl
dies unzutreffend ist.
Eine diagnostische Methode mit hohem α-Risiko legt häufig ein verdächtiges Ergebnis nahe, obwohl dies nicht zutrifft ("Fehlalarm"). Oder: Ein Prüfer mit hohem α-Risiko ist besonders streng; dann werden auch zahlreiche gut vorbereitete Kandidaten negativ
beurteilt.
Unter Spezifität versteht man die Wahrscheinlichkeit, mit welcher der Test in der
Gesamtheit der objektiv nicht kranken Untersuchten auch ein negatives
Testergebnis anzeigt.
Tests mit hoher Spezifität haben einen
geringen Fehler 1. Art.
Fehler 2. Art
β-Fehler, type II error: Die Merkmalsverteilung der Stichproben kann dazu veranlassen, die
Nullhypothese beizubehalten, obwohl sie in Wirklichkeit falsch ist
(z.B. wird vermutet, dass ein Medikament unwirksam ist, obwohl die beiden Testgruppen sich in Wahrheit unterscheiden). Die Höhe
dieser Irrtumswahrscheinlichkeit nennt man das Beta-Risiko.
 Man sagt auch, die Entscheidung ist bei Unterlaufen eines β-Fehlers falsch negativ. Auf eine medizinische
Diagnose bezogen, heißt das: die diagnostische Methode findet
nichts (klinischer Jargon: 'ohne Befund' - o.B.), obwohl die Person
objektiv krank ist.
Man sagt auch, die Entscheidung ist bei Unterlaufen eines β-Fehlers falsch negativ. Auf eine medizinische
Diagnose bezogen, heißt das: die diagnostische Methode findet
nichts (klinischer Jargon: 'ohne Befund' - o.B.), obwohl die Person
objektiv krank ist.
Eine Methode mit
hohem β-Risiko ist diagnostisch unempfindlich. Oder: Ein Prüfer mit hohem β-Risiko, d.h. geringer test power (=1-ß), ist
besonders mild ("Laissez-faire"-Typ); bei ihm kommen auch ungenügend vorbereitete Kandidaten
durch (was angenehm für Medizinstudent/inn/en, aber schlecht für deren zukünftige Patienten ist).
Unter Sensitivität versteht man die Wahrscheinlichkeit, mit welcher der Test in
der Gesamtheit der objektiv kranken Untersuchten auch ein positives
Testergebnis anzeigt.
Tests mit hoher Sensitivität haben einen
geringen Fehler 2. Art.
Bayes'sche Statistik
 Die Prüfungssituation ist nur ein Spezialfall der Unsicherheit, die generell auftritt,
wenn sich ein (vermuteter) Sachverhalt nicht direkt, sondern nur auf
dem Weg einer (eingeschränkt die "Wahrheit" abbildenden) Messmethode
offenbaren kann. Keine
Bestimmungsmethode bietet absolut 'richtige' Resultate zur Frage, wie
sicher eine Annahme über einen Sachverhalt tatsächlich zutrifft - über
die Fachkenntnisse eines Prüfungskandidaten, einen
Funktionsmechanismus, eine medizinische Diagnose, den
Gesundheitszustand einer Person oder anderes. Es verbleibt immer eine
Unsicherheit - z.B. kann eine Blutprobe falsch entnommen, bearbeitet,
gelagert, transportiert, umgefüllt, zugeordnet oder gemessen worden
sein, ohne dass dies aufgefallen wäre. (Der physiologische Gesamtzusammenhang
sowie individuelle Komponenten - Geschlecht, Alter, Genetik, Umwelt etc
- spielen ebenfalls eine Rolle und müssen in jedem Einzelfall
Berücksichtigung finden.)
Die Prüfungssituation ist nur ein Spezialfall der Unsicherheit, die generell auftritt,
wenn sich ein (vermuteter) Sachverhalt nicht direkt, sondern nur auf
dem Weg einer (eingeschränkt die "Wahrheit" abbildenden) Messmethode
offenbaren kann. Keine
Bestimmungsmethode bietet absolut 'richtige' Resultate zur Frage, wie
sicher eine Annahme über einen Sachverhalt tatsächlich zutrifft - über
die Fachkenntnisse eines Prüfungskandidaten, einen
Funktionsmechanismus, eine medizinische Diagnose, den
Gesundheitszustand einer Person oder anderes. Es verbleibt immer eine
Unsicherheit - z.B. kann eine Blutprobe falsch entnommen, bearbeitet,
gelagert, transportiert, umgefüllt, zugeordnet oder gemessen worden
sein, ohne dass dies aufgefallen wäre. (Der physiologische Gesamtzusammenhang
sowie individuelle Komponenten - Geschlecht, Alter, Genetik, Umwelt etc
- spielen ebenfalls eine Rolle und müssen in jedem Einzelfall
Berücksichtigung finden.)
Eine mathematische Formulierung zugrundeliegender Wahrscheinlichkeiten
wurde von dem im 18. Jahrhundert lebenden britischen Philosophen und
Mathematiker Thomas Bayes vorgeschlagen, nach dem zahlreiche
einschlägige Methoden und Begriffe benannt wurden, u.a. die Bayes'sche
Statistik. Diese beinhaltet Bayes'sche Wahrscheinlichkeiten (probabilities
p): Während eine Aussage in der klassischen Logik entweder falsch (Wert
p=0) oder richtig ist (Wert p=1), liegt eine Bayes'sche Wahrscheinlich
zwischen diesen Extremen (z.B. p=0,2: Dies ziegt keine Gewissheit an,
wohl aber eine Wahrscheinlichkeit).
Wie wahrscheinlich eine Hypothese, Diagnose, Vermutung ist, wird nach Bayes von zwei Komponenten bestimmt:
 Was wir über einen Sachverhalt schon wissen (prior knowledge) und eine entsprechende pretest probability ergibt, und
Was wir über einen Sachverhalt schon wissen (prior knowledge) und eine entsprechende pretest probability ergibt, und
neue Beobachtungen (z.B. Laborbefund), die dieses Wissen beeinflussen und die posttest probability verändern (erhöhen oder senken).
Das Bayes'sche Theorem (auch: Bayles' rule) findet in verschiedenen
Variationen und Anwendungen Anwendung. Es nutzt Eingangs- und bedingte
Wahrscheinlichkeiten und prüft auf diese Weise Hypothesen, darstellbar
in der Form von 4-Felder-Matrices:

Abbildung: 4-Felder-Matrix zu Testergebnissen: Beurteilung eines Klassifikators (dieser ordnet zu einem von zwei Kategorien zu)
r = richtig  f = falsch p = positiv n = negativ
f = falsch p = positiv n = negativ
Sensitivität (sensitivity)
ist definiert als der Anteil der richtig positiven Befunde (Test sagt:
"krank") bezogen auf die Gesamtzahl der kranken Personen:
Sens = rp / (rp + fn)
Die Aussage der Sensitivität ist also: Wie sicher
werden kranke Personen als solche erkannt?
Spezifität (specificity) ist definiert als der Anteil der
richtig negativen Befunde (Test sagt: "nicht krank") bezogen auf die Gesamtzahl der gesunden
Personen:
Spez = rn / (rn + fp)
Die Aussage der Spezifität lautet daher: Wie sicher werden nicht kranke Personen als solche erkannt?
Der prädiktive Wert
gibt an, wie hoch der Prozentsatz der zutreffenden (negativen oder
positiven) Befunde an der Gesamtheit der (negativen oder positiven)
Situationen ist (ein Maß für die Wahrscheinlichkeit richtiger
Diagnosen).
Der positive prädiktive Wert (PPV, positive predictive value) ist definiert als die Zahl richtig positiver zur Gesamtzahl an
positiven Testergebnissen:
PPV = rp / (fp + rp)
Die Aussage lautet: Wie hoch ist der Anteil tatsächlich kranker
Personen in der Gruppe der Personen, die der Test als krank deklariert?
Der negative prädiktive Wert (NPV, negative predictive value) ist
definiert als die Zahl richtig negativer zur Gesamtzahl an negativen
Testergebnissen:
NPV = rn / (fn + rn)
Aussage: Wie hoch ist der Anteil tatsächlich gesunder
Personen in der Gruppe der Personen, die der Test als gesund
deklariert?
Populationen, die sich im betreffenden
Zustand unterscheiden, überschneiden sich in Hinblick auf die Messgröße (diagnostischer
Test, Prüfungsergebnis,..).
Man kann die Fehlerwahrscheinlichkeit 2. Art durch Vergrößerung
des Stichprobenumfangs zwar verringern, aber das verursacht einen steigenden
Aufwand (größere Kosten).
Es geht also um
den erwarteten Nutzen diagnostischer Tests.
Dabei ist zu beachten, dass die diagnostische Aussage
nie 'sicher', sondern nur wahrscheinlich sein kann. Die hier
besprochenen Konzepte der Sensitivität, Spezifität und des prädiktiven
Wertes sind auf Tests (wissenschaftlich, labormedizinisch etc)
anwendbar, die eine Ja-Nein-Antwort auf die Frage geben, ob ein
bestimmter Zustand (z.B. eine Erkrankung) vorliegt oder nicht.
Man kann die Treffsicherheit, mit der auf das Vorliegen eines
vermuteten Zustandes (z.B. einer Erkrankung) geschlossen werden kann,
erhöhen, indem man Wahrscheinlichkeiten, die in der gegebenen Population vorliegen, kombiniert mit Ergebnissen von Tests. Denn zusätzlich zum Ergebnis eines diagnostischen Tests spielt auch die Wahrscheinlichkeit eine Rolle, mit der eine Person - unabhängig von Testergebnissen, z.B. auf Grund von Alters, Geschlecht, Lebensweise etc - einen bestimmten Zustand aufweist, z.B. für das Vorliegen eines Diabetes (A-priori-Wahrscheinlichkeit, pretest odds).
Multipliziert man diese Wahrscheinlichkeit mit dem entsprechenden Quotienten aus
Sensitivität / (1-Spezifität), ergibt sich eine - sozusagen
korrigierte, verbesserte - A-posteriori-Wahrscheinlichkeit (post-test odds) für das Vorliegen eines bestimmten Zustandes bei einer bestimmten Person (Bayes-Theorem).
Die
a-priori-Wahrscheinlichkeit gibt also an, wie wahrscheinlich in einem
Kollektiv Personen eine bestimmte Erkrankung aufweisen (bevor noch
Tests durchgeführt werden); die Durchführung entsprechender Tests
verbessert diesen Erwartungswert auf eine korrigierte
a-posteriori-Wahrscheinlichkeit. Es resultiert ein Plausibilitätsquotient (Likelihood-Quotient, likelihood ratio LR) - dieser gibt an, wie sehr sich der Erwartungswert verändert hat.
Der LR-Wert ist ein Multiplikator, dessen Wert zwischen Null und
Unendlich liegen kann. Beträgt er 1, hat sich nichts an der
Erwartungswahrscheinlichkeit verändert.
Liegt
|LR] unter 1, hat sich die Wahrscheinlichkeit für das Vorliegen der
Erkrankung erniedrigt; die entsprechende LR- berechnet sich aus
LR- = (1 - Sens) / Spez
(Wahrscheinlichkeit einer kranken Person mit negativem Testresultat dividiert durch Wahrscheinlichkeit einer nicht kranken Person mit negativem Testresultat)
Liegt
|LR] über 1, hat sich die Wahrscheinlichkeit für das Vorliegen der
Erkrankung erhöht; die entsprechende LR+ berechnet sich aus
LR+ = Sens / (1 - Spez)
(Wahrscheinlichkeit einer kranken Person mit positivem Testresultat dividiert durch Wahrscheinlichkeit einer nicht kranken Person mit positivem Testresultat)
Ermittelte Messwerte (in Blut, Serum, Harn u.a.) werden danach beurteilt, ob sie in einem festgesetzten Referenzbereich
liegen und damit diagnostisch unverdächtig sind. Liegen sie außerhalb
dieses Bereichs, kann dennoch ein Fehler 1. Art vorliegen (gesunder
Mensch mit "verdächtigem" Laborbefund). Umgekehrt garantiert ein Wert
innerhalb des Bereichs nicht, dass keine Krankheit vorliegt (es kann
ein Fehler 2. Art vorliegen); beides kann jeweils nur mit einer
bestimmten Wahrscheinlichkeit angenommen werden.
Mit der Anwendung biometrischer
Verfahren ist in jedem Fall die Planung der
Untersuchung verbunden, da eine sinnvolle Datenauswertung direkt
mit der 'Philosophie' der Studie zusammenhängt. So sollten die
Elemente der Stichproben (untersuchte Patienten) in allen
anderen Merkmalen (als dem Unterscheidungskriterium, z.B.
Kopfschmerzdauer) möglichst nicht verschieden sein (d.h. gleiche
Alters-, Geschlechts-, Krankheitsverteilung usw.).
Dies erreicht man durch Randomisierung,
d.h. zufällige Zuordnung von Probanden zu den Testgruppen, um
(unbeabsichtigte) systematische Fehler (Trend, bias) zu
vermeiden - solche Fehler täuschen sonst einen Effekt vor, der
in Realität nicht besteht. Dies ist eine Anforderung an das Studiendesign.
Verfahren zur Hypothesentestung müssen entsprechend der Natur der Datenverteilung gewählt werden. Man unterscheidet
verteilungsabhängige (
parametrische) statistische Verfahren
(parametric tests), z.B. der
t-Test (Student's t), der zwei, und
die
ANOVA (analysis of variance), die zwei oder mehr
normalverteilte Stichproben (Gauss-Glockenkurve, s.
oben) vergleichen lässt;
verteilungsunabhängige (
parameterfreie) Verfahren
(non-parametric tests), z.B. der
Mann-Whitney U-,
Wilcoxon-,
Kruskal-Wallis- oder
Friedman-Test: Nicht die gemessenen Werte an sich werden verglichen, sondern aufgrund
dieser Werte ermittelte
Rangzahlen
(Beispiel Altersverteilung: Statt dem Alter in Jahren - z.B. 9 bis 90
Jahre - werden die Ränge der Datenpunkte (1 bis x) verglichen). Diese
Verfahren werden genutzt, wenn die Werte der Stichproben
nicht normalverteilt sind.
Vergleicht man
asymmetrisch verteilte Stichproben, sollte man
nicht-parametrische Tests zur Hypothesenverifizierung einsetzen.
Der
Grad der Asymmetrie, also die "Schiefe"
(skewness) einer Verteilung kann durch eine entsprechende Kennzahl quantifiziert werden, beispielsweise Pearson's S:
wobei µ = Mittelwert, M = Medianwert und SD = Standardabweichung. Der
Wert von S kann zwischen -1 und +1 liegen; ist die Verteilung
symmetrisch, beträgt [S] gleich Null - Mittelwert und Medianwert fallen
zusammen, [µ-M] muss daher 0 sein.
Von
negativer Schiefe spricht man bei einer linksschiefen / rechtssteilen Verteilung; von
positiver
Schiefe bei einer rechtsschiefen / linkssteilen Verteilung (z.B. <Abbildung oben).
Rechtsschiefe Verteilungen zeigen oft (wenn auch nicht immer) ein
positives, linksschiefe ein negatives S.

Es ist legitim, Daten so umzuwandeln, dass aus einer schiefen Verteilung
eine normalverteilte wird, z.B. durch Logarithmierung. Dann können (auch)
parametrische Tests zur Anwendung kommen.
Entscheidend für die Hypothesenprüfung ist der
p-Wert (
Bedeutung s.
oben), der bei allen diesen Tests ermittelt werden kann.
Es gibt zahlreiche weitere Tests, die im naturwissenschaftlich-medizinischen Bereich Anwendung finden, z.B.
Der
Chi-Quadrat-
(chi-squared) Test: Dieser vergleicht den Unterschied zwischen beobachteter und erwarteter (Nullhypothese wahr) Stichprobenverteilung
; je größer der Unterschied, desto größer der Χ
2-Wert (bei fehlender Ungleichheit ist [Χ
2]=0). Auch bei diesem Test kann man den p-Wert ermitteln, um die Wahrscheinlichkeit
anzugeben, dass in Wirklichkeit kein Unterschied zwischen den
Stichproben besteht.

 Messwerte können qualitativ (z.B. männlich / weiblich) oder quantitativ
dargestellt werden, letztere diskret (z.B. Leukozytenzahl) oder stetig
(z.B. Betrag des Blutdrucks). Die Art der Darstellung einer Häufigkeitsverteilung sowie passende statistische Verfahren hängen
von der Art des Merkmals und seiner Verteilung ab. Biometrie wendet statistische Methoden auf
die Lösung biologischer Probleme an. Man unterscheidet deskriptive
(Mittelwert, Varianz) und induktive Statistik (Hypothesenverifizierung, Wahrscheinlichkeitsrechnung) Messwerte können qualitativ (z.B. männlich / weiblich) oder quantitativ
dargestellt werden, letztere diskret (z.B. Leukozytenzahl) oder stetig
(z.B. Betrag des Blutdrucks). Die Art der Darstellung einer Häufigkeitsverteilung sowie passende statistische Verfahren hängen
von der Art des Merkmals und seiner Verteilung ab. Biometrie wendet statistische Methoden auf
die Lösung biologischer Probleme an. Man unterscheidet deskriptive
(Mittelwert, Varianz) und induktive Statistik (Hypothesenverifizierung, Wahrscheinlichkeitsrechnung)
Deskriptive
Statistik ermittelt Häufigkeitsverteilungen und gibt
Streumaße an, wie den arithmetrischen Mittelwert (AMW), den Modalwert oder den
Medianwert. Der AMW liegt
beim häufigsten Wert einer Normalverteilung (Gauss-sche Glockenkurve), die
Standardabweichung (SD) kennzeichnet die Streuung der Messwerte um den
Mittelwert: Der Bereich AMW ± 1 SD umfasst 68,2%; AMW ± 2 SD 95,4%; und
AMW ± 3 SD 99,7% aller Beobachtungen. Bei einer perfekten symmetrischen Verteilung haben Modal-, Median- und Mittelwert den identischen Betrag. Teilt der AMW die Verteilung nicht in zwei gleich
große Hälften, liegt keine Normalverteilung vor; der
Medianwert trennt die oberen von den unteren 50% der Verteilung, der Modalwert ist der häufigste Wert in der Stichprobe.
Box and whisker-Plots zeigen die
25- und 75%-Perzentile (box), definierte Minimal- und Maximalwerte
(whiskers) und (individuell) außerhalb liegende Ausreißer
Absolutgenauigkeit
(accuracy) gibt die Richtigkeit einer Messung als die Differenz
zwischen dem wahren Wert und dem Mittelwert der Messergebnisse an,
Präzision (precision) die Wiederkehrgenauigkeit als Verteilungsbreite
(schmale Streuung → hohe Präzision). Das
Konfidenzintervall gibt an, in welchem Bereich der wirkliche Mittelwert
(derjenige der gesamten Population) liegt
Schließende
Statistik errechnet, wie wahrscheinlich vermutete Sachverhalte
zutreffen (Hypothesenverifizierung). Dazu erhebt man Daten an
Zufallsstichproben, die mittels Auswahlverfahren ausgesucht werden. Der p-Wert quantifiziert die Wahrscheinlichkeit der Nullhypothese, d.h. dass sich die verglichenen Kollektive hinsichtlich des untersuchten Merkmals nicht
unterscheiden (Sicherheit: p=1,0; Unmöglichkeit: p=0,0). Liegt er z.B.
bei 0,05, heißt das, dass der Effekt in einem von 20 Untersuchungen
(5%) durch Zufall auftreten würde, üblicherweise gilt das Ergebnis dann
als signifikant. Ob der Effekt auch relevant ist, hängt vom Zusammenhang ab
Fehler 1. Art
(α-Fehler) heißt, die Nullhypothese wird zurückgewiesen, obwohl sie in
Wirklichkeit richtig ist (α-Risiko): Die Entscheidung ist falsch
positiv (Vermutung: Person krank, obwohl das nicht zutrifft:
"Fehlalarm"). Spezifität ist
die Wahrscheinlichkeit, mit der der Test in der Gruppe der Gesunden korrekterweise ein negatives Ergebnis anzeigt;
Tests mit hoher Spezifität haben einen geringen Fehler 1. Art
Fehler 2. Art (β-Fehler) bedeutet, die Nullhypothese wird beibehalten, obwohl sie in Wirklichkeit falsch ist (β-Risiko): Die Entscheidung ist falsch negativ (diagnostisch unempfindlich - "o.B.", obwohl die Person objektiv krank ist). Sensitivität
ist die Wahrscheinlichkeit, mit der der Test in der Gruppe der Kranken korrekterweise ein
positives Testergebnis anzeigt; Tests mit hoher Sensitivität haben
einen geringen Fehler 2. Art
Messwerte werden in erster Linie danach beurteilt, ob sie in einem
festgesetzten Referenzbereich liegen (diagnostisch unverdächtig sind).
Liegen sie innerhalb des Referenzbereichs, kann dennoch ein Fehler 2. Art vorliegen (kranker Mensch mit unverdächtigem Befund); liegt er außerhalb, kann dennoch ein Fehler 1. Art vorliegen (gesunder Mensch mit verdächtigem Befund). Eine diagnostische Aussage kann nie zu 100% sicher sein. Der prädiktive Wert ist ein Maß für die Wahrscheinlichkeit richtiger Diagnosen: Er gibt
an, wie hoch der Prozentsatz der zutreffenden (negativen oder
positiven) Befunde an der Gesamtheit der (negativen oder positiven)
Situationen ist
Hypothesenverifizierung braucht Randomisierung (zufallsgeleitete Zuordnung
von Probanden zu Testgruppen), um systematische Fehler (die einen nicht
existierenden Effekt vortäuschen könnten) zu vermeiden (Anforderung an
das Studiendesign). Bei Normalverteilungen (Glockenkurve) können
verteilungsabhängige (parametrische) statistische Verfahren, z.B.
Student's t-Test oder ANOVA (analysis of variance) zur Anwendung
kommen. Bei anderen - negativ (links-) oder positiv (rechtsschiefen) -
Verteilungen verwendet man verteilungsunabhängige
(parameterfreie) Verfahren, z.B. Mann-Whitney U-, Wilcoxon-,
Kruskal-Wallis- oder Friedman-Test (nicht gemessene Werte, sondern
Rangzahlen werden verglichen). Der Grad der Asymmetrie (skewness) der
Verteilung kann durch eine entsprechende Kennzahl quantifiziert werden,
beispielsweise Pearson's S. Man kann schiefe zu Normalverteilungen
umformen, z.B. durch Logarithmierung
|
 Die Informationen in dieser Website basieren auf verschiedenen Quellen:
Lehrbüchern, Reviews, Originalarbeiten u.a. Sie
sollen zur Auseinandersetzung mit physiologischen Fragen, Problemen und
Erkenntnissen anregen. Soferne Referenzbereiche angegeben sind, dienen diese zur Orientierung; die Grenzen sind aus biologischen, messmethodischen und statistischen Gründen nicht absolut. Wissenschaft fragt, vermutet und interpretiert; sie ist offen, dynamisch und evolutiv. Sie strebt nach Erkenntnis, erhebt aber nicht den Anspruch, im Besitz der "Wahrheit" zu sein.
Die Informationen in dieser Website basieren auf verschiedenen Quellen:
Lehrbüchern, Reviews, Originalarbeiten u.a. Sie
sollen zur Auseinandersetzung mit physiologischen Fragen, Problemen und
Erkenntnissen anregen. Soferne Referenzbereiche angegeben sind, dienen diese zur Orientierung; die Grenzen sind aus biologischen, messmethodischen und statistischen Gründen nicht absolut. Wissenschaft fragt, vermutet und interpretiert; sie ist offen, dynamisch und evolutiv. Sie strebt nach Erkenntnis, erhebt aber nicht den Anspruch, im Besitz der "Wahrheit" zu sein.
 Beschreibende Statistik
Beschreibende Statistik  Quartilsabstand
Quartilsabstand 

 Übersichtsgraphik: Klinisch-chemische Normbereiche
Übersichtsgraphik: Klinisch-chemische Normbereiche